
Sections
- Introduction
- Slowly Changing Dimensions Type 2
- Example case scenario
- SCD Type 2 (Updates)
- SCD Type 2 (Inserts)
- SCD Type 2 (Deletes)
- Conclusion
Introduction
As businesses strive to make informed decisions based on accurate and historical data, managing evolving data within a dimensional model becomes imperative. SCD Type 2 provides an effective solution by capturing and preserving historical changes in data over time.
In this blog, we will explore the robust combination of Delta tables and the Kimball methodology to effortlessly handle SCD Type 2 scenarios. The Kimball approach, developed by the data warehousing pioneer Ralph Kimball, emphasizes a dimensional modelling technique that aligns with business requirements while maintaining simplicity and usability.
We will dive into the fundamentals of SCD Type 2, understanding its importance in data warehousing. Then we will introduce Delta tables, a powerful data management feature provided by modern data platforms such as Delta Lake, enabling efficient change tracking and data versioning.
Next, we will guide you through the step-by-step implementation of SCD Type 2 using Delta tables, following the principles outlined by the Kimball approach. You will learn how to load dimension delta tables to accommodate historical changes and handle various scenarios, such as capturing new records, updating existing ones, handling deletions from source data and managing expired or inactive records.
Throughout this blog, we will provide practical examples and code snippets, making it easier for you to grasp the concepts and apply them in your data warehousing projects. By the end, you will have a solid understanding of how to effectively implement SCD Type 2 using Delta tables and the Kimball approach, empowering you to build reliable and scalable data architectures that cater to the evolving needs of your organization.
Slowly Changing Dimensions Type 2
SCD Type 2 addresses the challenge of managing and preserving historical changes in dimensional data over time.
In a dimensional model, dimensions represent the various attributes or characteristics of the business entities being analyzed, such as customers, products, or locations. These dimensions often undergo changes that need to be tracked and maintained for historical reporting and analysis purposes.
SCD Type 2 provides a solution for handling these changes by creating a new row in the dimension table whenever a significant attribute value changes. This approach allows the retention of both the current and historical versions of a dimension record, providing a comprehensive view of the data’s evolution.
Key features and principles of SCD Type 2 by Ralph Kimball include:
- Surrogate Keys: SCD Type 2 introduces surrogate keys, which are artificial keys used to uniquely identify each version of a dimension record. These surrogate keys facilitate the efficient tracking and referencing of historical changes.
- Start and End Dates: Each row in the dimension table includes a start date and an end date. The start date represents the effective date of the record, while the end date indicates when the record is no longer active or valid. By specifying the end date as open-ended or using a specific value like ‘9999-12-31,’ the current version of the record can be easily identified.
- Slow Changes: SCD Type 2 focuses on handling slow changes, which are modifications that occur infrequently and necessitate the creation of a new record version. Examples of slow changes include changes in customer addresses, product descriptions, or employee promotions.
- Historical Integrity: SCD Type 2 ensures the integrity of historical data by preventing updates to existing records. Instead, it creates new records with updated attribute values while maintaining the previous versions.
- Type 2 Dimension Table Structure: The dimension table for SCD Type 2 includes attributes such as the surrogate key, natural key, attribute values, start date, and end date. The table evolves over time, capturing the historical changes without altering or deleting existing data.
Example Case Scenario
Consider a company ABC require to keep track of Sales Dimensions for any change happening over time. The Analytics Engineer team suggests using SCD Type 2 with delta tables. Also, they need to track if any record was deleted in the source dataset and mark it.
Here we are keeping track of data from Silver Layer to Gold Layer
DimSales
SurrogateKey | DimId | Col1 | Col2 | Col3 | Hash | CurrentFlag | DeletedFlag | EffectiveFromDate | EffectiveToDate |
| 100 | 1 | 200 | 500 | 800 | d43f… | Y | N | 2023-05-12 | 2999-12-31 |
| 102 | 6 | 300 | 900 | 250 | 214f… | Y | N | 2023-05-12 | 2999-12-31 |
| 103 | 13 | 900 | Null | 700 | 3c47… | Y | N | 2023-05-12 | 2999-12-31 |
| 104 | 43 | 340 | 359 | 9032 | rc9f… | Y | N | 2023-05-12 | 2999-12-31 |
SCD Type 2 (Updates)
First, we will set up the necessary Delta Tables that will serve as the Silver New Data coming and the Gold Data Dimension that will role-play as the target.
# Libraries Needed for the demo from delta.tables import * from pyspark.sql.functions import * from pyspark.sql.window import Window # Path Azure Data lake gold_path = 'abfss://deltadev01@…/synapse/workspaces/synapsedeviterations/warehouse/gold/DimSales/' silver_path= 'abfss://deltadev01@…/synapse/workspaces/synapsedeviterations/warehouse/silver/updates/
Create Gold demo data:
columns = ["SurrogateKey","DimId", "Col1", "Col2","Col3","Hash", "CurrentFlag","DeletedFlag" , "EffectiveFromDate" , "EffectiveToDate" ] data_g = [(100,"1", "200" , "500" , "800" , "d43fac69ca61701ab7e73bcd3243d3eee16d17fd9b272e771219748f44e296bc" , "Y","N" ,"2023-05-12","2999-12-31" ) , (102,"6", "300" , "900" , "250" , "214f2d6d2245dfc8f7e23cb9c45d6a3ceb8d920e6894902f38a0e5c8abd3bf60" , "Y","N","2023-05-12","2999-12-31" ) ,(103,"13", "900" , None , "700" , "3c47b4483777dc59a611f1623c1c459c2ddd0afe8089af993701fda05f561127" , "Y","N","2023-05-12","2999-12-31" ) ,(104,"43", "340" , "359" , "9032" , "rc9fe69c1076002d1d9e504a8aabb57cf57e8cf6a5ab56220a6ab7010b96b6e8" , "Y","N","2023-05-12","2999-12-31")]
Create Silver demo data:.
Here, it is important to mention that the SurrogateKey that is coming from silver is empty at this stage and will be created when moving to the final target. Also, note that at this moment, Hash is also empty and will be generated with the data coming from Col1, Col2, and Col3. This will tell us when any of these silver columns are different from the target gold data.
columns = ["SurrogateKey","DimId", "Col1", "Col2","Col3","Hash", "CurrentFlag","DeletedFlag" , "EffectiveFromDate" , "EffectiveToDate" ] data_s = [("","1" ,"200" , "500" , "800" , "" , "Y","N" ,"2023-05-12","2999-12-31" ) , ("","6", "300" , "900" , "250" , "" , "Y","N","2023-05-12","2999-12-31" ) ,("","13", "100" , None , "700" , "" , "Y","N","2023-06-08","2999-12-31") ,("","59", "1500" , "2000" , "800" , "" , "Y","N","2023-06-08","2999-12-31")]
Now let us create both data frames:
gold = spark.createDataFrame(data_g).toDF(*columns) silver = spark.createDataFrame(data_s).toDF(*columns)
Create hash for Col1, Col2 and Col3 using sha2 function with a bit length of 256
HashCols = ['Col1', 'Col2', 'Col3'] silver = silver.withColumn("Hash", lit(sha2(concat_ws("~", *HashCols), 256)))
Find out more about Hash here
Create a Temporary Surrogate Key for the silver data frame:
The integration of surrogate keys enhances the tracking and referencing of historical changes, allowing for efficient querying and analysis. These artificial keys enable you to uniquely identify each version of a dimension record, ensuring accurate analysis across different timeframes.
Previous state with empty Surrogate Key
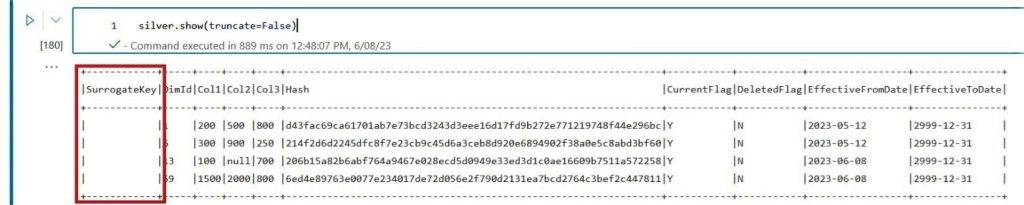
There are several methods for the creation of a surrogate key. We will use the Window and row_number function order by the ‘DimId’ and ‘Hash’ from Silver. The objective is to obtain a unique frame that will generate unique values for the entire final table and future incoming data.
This temporary Surrogate Key will be used to renumber the final key and avoid collision with existing keys adding the last maximum key in gold. This will create a virtual accumulator for incremental loads.
# Keys for DimSales keys = ['DimId', 'Hash'] # Build the dimension surrogate key w = Window().orderBy(*keys) silver = silver.withColumn("SurrogateKey", row_number().over(w)) silver = silver.withColumn("SurrogateKey",col("SurrogateKey").cast('long'))
Find out more about PySpark Window Functions here
Tip: Make Sure the newly generated Surrogate Key is the same datatype as the target data

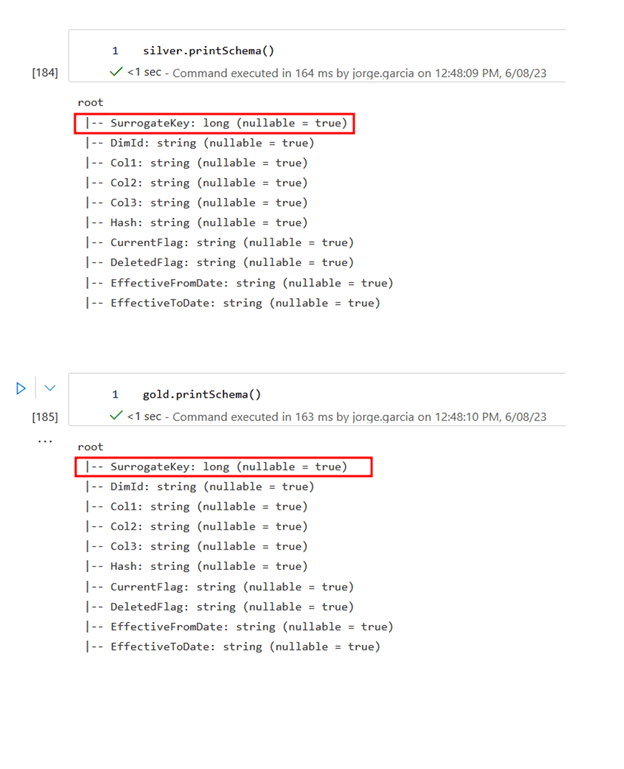

As shown at the beginning of the blog let’s revise our silver and gold data frames that now include the Temporary Surrogate Key and new Hash for silver data.

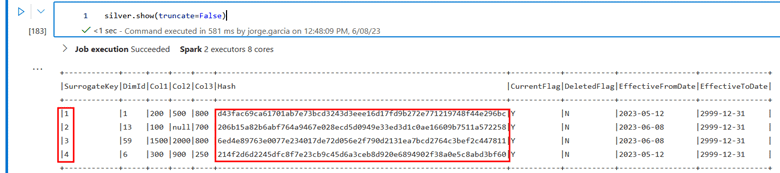
At this point, we successfully have created the data necessary for our Delta Tables. The next step is to create the delta tables. We are using the initial gold_path and silver_path in our Azure Data Lake folders.
# Write Dataframe as Delta Table (gold) if not DeltaTable.isDeltaTable(spark, gold_path): gold.write.format("delta").mode("overwrite").save(gold_path) # Write Dataframe as Delta Table (silver) if not DeltaTable.isDeltaTable(spark, silver_path): silver.write.format("delta").mode("overwrite").save(silver_path)
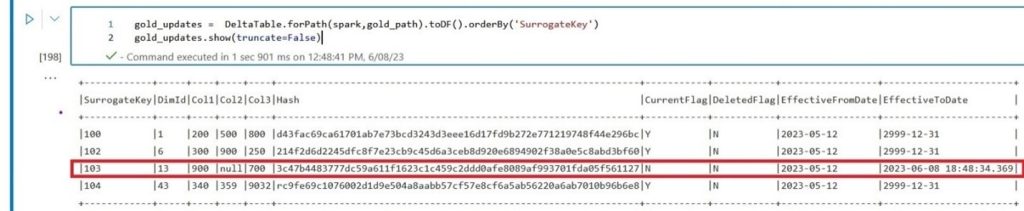
Before I present the code for the next section, let’s understand the objective and how to get there. We need to update the status of any record that has changed from previous loads and flag that as CurrentFlag = ‘N’, in our example DimId =13 comes with 1 new sale for Col1.
Note: We will be able to catch any change for the Col1, Col2, and Col3 with hash
Gold
Silver
DimId | Col1 | Col2 | Col3 | Hash | DimId | Col1 | Col2 | Col3 | Hash |
| 13 | 900 | Null | 700 | 3c47… | 13 | 100 | Null | 700 | 3c47… |
Also, silver brings a new record that is not present in the target dataset and that needs to be inserted.
Silver
SurrogateKey | DimId | Col1 | Col2 | Col3 | Hash | CurrentFlag | DeletedFlag | EffectiveFromDate | EffectiveToDate |
| 3 | 59 | 1500 | 2000 | 800 | 6ed4… | Y | N | 2023-06-08 | 2999-12-31 |
There are different techniques to achieve this, however, I found that using Left Anti join can be solved easily. Left Anti Join returns only those rows in the left(silver) rowset that have no matching row in the right(gold) rowset.
The match condition for the join must ensure unique values and every query against the Dimension needs to filter to CurrentFlag = ‘Y’ AND DeletedFlag = ‘N’. This statement ensures that the universe that is going to be modified is only Current and not marked deleted from previous ETL loads.
To obtain unique values we will use DimId Key and Hash
Silver
Gold
SurrogateKey | DimId | Hash | CurrentFlag | DeletedFlag | SurrogateKey | DimId | Hash | CurrentFlag | DeletedFlag |
| 1 | 1 | d43f… | Y | N | 100 | 1 | d43f… | Y | N |
| 2 | 13 | 206b… | Y | N | 102 | 6 | 214f… | Y | N |
| 3 | 59 | 6ed4… | Y | N | 103 | 13 | 3c47… | Y | N |
| 4 | 6 | 214f … | Y | N | 104 | 43 | rc9f… | Y | N |

SurrogateKey | DimId | Hash | CurrentFlag | DeletedFlag |
| 2 | 13 | 206b … | Y | N |
| 3 | 59 | 6ed4… | Y | N |
condition = ['DimId', 'Hash', 'CurrentFlag', 'DeletedFlag'] RowsToUpdate = silver \ .alias("source") \ .where("CurrentFlag = 'Y' AND DeletedFlag = 'N'") \ .join(gold.alias("target"),condition,'leftanti') \ .select(*columns) \ .orderBy(col('source.DimId'))

Before continuing we will increment the Surrogate for the new records and after that, we will merge the new changes to the gold delta table.
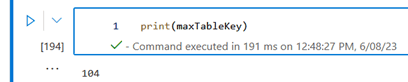
# Retrieve maximum surrogate key in gold delta table maxTableKey = DeltaTable.forPath(spark, gold_path).toDF().agg({"SurrogateKey":"max"}).collect()[0][0]
# Increment surrogate key in stage table by maxTableKey RowsToUpdate = RowsToUpdate.withColumn("SurrogateKey", col("SurrogateKey") + maxTableKey)
To avoid collision with keys:
104 + 2 = 106
104 + 3 = 107

# Merge statement to expire old records DeltaTable.forPath(spark, gold_path).alias("original").merge( source = RowsToUpdate.alias("updates"), condition = 'original.DimId = updates.DimId' ).whenMatchedUpdate( condition = "original.CurrentFlag = 'Y' AND original.DeletedFlag = 'N' AND original.Hash <> updates.Hash", set = { "CurrentFlag": "'N'", "EffectiveToDate": lit(current_timestamp()) } ).execute()
SCD Type 2 (Inserts)
After DimId=13 is expired, we are still carrying over in the data frame the new records that need to be inserted.
# Insert all new and updated records RowsToUpdate.select(*columns).write.mode("Append").format("delta").save(gold_path)

SCD Type 2 (Deletes)
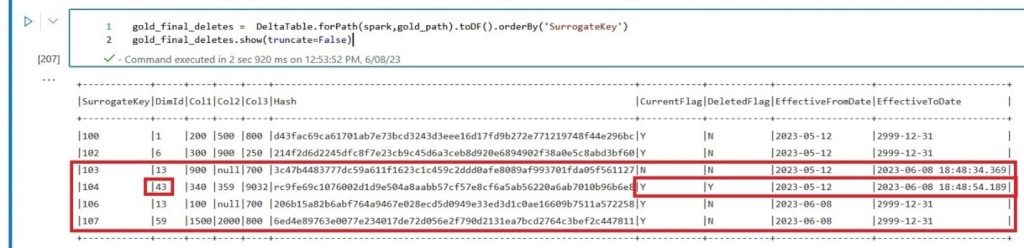
The final step will include the deletes. Suppose that source data is being deleted, to conform with our complete solution for the Data Lakehouse we will record that historic change as well.
We will utilize a similar solution to the Updates. In this case, whichever data in gold that is not present in the total incoming new dataset we will assume was deleted from the source. Remember that silver data is loaded with the complete set of rows CurrentFlag =’ Y’ AND DeletedFlag=’N’.
Note that we are using DimId as a join condition and the last effective day until deletion is today.
Gold
Silver
| DimId | CurrentFlag | DeletedFlag | DimId | CurrentFlag | DeletedFlag |
| 1 | Y | N | 1 | Y | N |
| 6 | Y | N | 13 | Y | N |
| 13 | Y | N | 59 | Y | N |
| 43 | Y | N | 6 | Y | N |

DimId | CurrentFlag | DeletedFlag |
| 43 | Y | N |
RowsToDelete = gold.alias('gold').where("CurrentFlag = 'Y' AND DeletedFlag = 'N'") \ .join(silver.alias('silver'), col('silver.DimId') == col('gold.DimId'), "leftanti")

# Merge statement to mark as deleted records DeltaTable.forPath(spark, gold_path).alias("original").merge( source = RowsToDelete.alias("deletes"), condition = 'original.DimId = deletes.DimId' ).whenMatchedUpdate( condition = "original.CurrentFlag = 'Y' AND original.DeletedFlag = 'N'", set = { "DeletedFlag": "'Y'", "EffectiveToDate": lit(current_timestamp()) } ).execute()
Finally, the update, insert and delete records are successfully logged and flagged.
Note that in this solution we assume that to show the last Current record that existed before deletion we use CurrentFlag = ‘Y’ AND DeletedFlag = ‘Y’ in case we have historic data for the same record and there is a need to bring the last existing record.
As we have mentioned there are different approaches and techniques for instance grouping DimId and bringing the max by EffectiveToDate. You can apply whichever works best for your specific requirements.
Conclusion
In conclusion, we have explored the powerful combination of Slowly Changing Dimensions Type 2, Delta tables, surrogate keys, and PySpark within the Delta Lakehouse architecture. This blog has provided you with a comprehensive understanding of how to effectively implement SCD Type 2 in your data warehousing projects, leveraging modern technologies and following industry best practices.
By implementing SCD Type 2 according to Ralph Kimball’s approach, organizations can achieve a comprehensive view of dimensional data, enabling accurate trend analysis, comparison of historical performance, and tracking of changes over time. It empowers businesses to make data-driven decisions based on a complete understanding of the data’s evolution, ensuring data integrity and reliability within the data warehousing environment.
Start implementing SCD Type 2 with Delta Lakehouse today and revolutionize your data warehousing capabilities.
