
Sections
Delta Lake made an entrance into Azure Synapse Analytics by becoming generally available with Apache Spark 3.1 in September 2021. Its arrival provided expanded capabilities for the data lakehouse architecture in Azure Synapse Analytics bringing features such as ACID transactions, the MERGE statement, and time travel. With the Spark engine providing scalable computing and unified experience and Azure Data Lake Storage providing fast and affordable storage, the lakehouse offers a flexible and cost-effective option for the modern data warehouse.
While the combination of Delta Lake and Serverless SQL Pools quickly became a powerful duo in the toolbelt of many data engineers, it was hard not to peek over the fence and be envious of the advanced features Azure Databricks has to offer. That is why many Spark enthusiasts were met with excitement when Azure Databricks announced their commitment to fully expand the open-sourcing of Delta Lake features, starting with Delta Lake 2.0. With Microsoft continuing to be responsive in keeping newer versions of Delta Lake rolling out with each update to Spark Pools, some of these features have made their way into Synapse.
We will cover some of these new features and updates in Delta Lake since the initial release into Azure Synapse Analytics.
For a full listing of all the changes for each Delta Lake release, check out the GitHub releases page for the open-source Delta Lake project. The Delta Lake documentation is also a great source of information for both getting started and understanding features.
Optimize
Release: Delta Lake 1.2.0 | Minimum Synapse Runtime: Apache Spark 3.2
One of the biggest benefits of using the Spark engine is the capability of distributed compute using many worker nodes. Worker nodes will often write many small files to a Delta table folder when performing upserts into that table. Compacting is a common strategy that allows for consolidating many smaller parquet files into larger ones within a Delta table’s folder. This will result in faster read performance when querying a Delta table as your query engine will now have fewer files to scan on read.
Before the release of the optimize feature, compacting files was achieved by repartitioning a Delta table into a set number of files specified by the Spark notebook developer. This code for this process has now been simplified with the OPTIMIZE command.
Here is an example of a Delta table within Azure Data Lake Storage before using the optimize feature. There are 16 parquet files, each roughly 72 Mb in size.
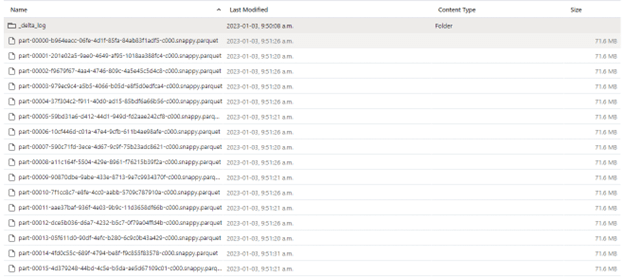
Below are a couple of examples of utilizing the OPTIMIZE command by both Delta table name and path where “delta_table1” is the name of the Delta table.
%%sql --Compacting files using the spark database and table name OPTIMIZE default.delta_table1 --Compacting files using the delta table folder location OPTIMIZE '/demofs/demo/delta_table1'
After running either the command on line 3 or line 6, two new files that contain the contents of the Delta table are written. Only these files will be scanned next time a read operation is run. By default, the OPTIMIZE command will target a 1 Gb file size.

The code for the optimize feature is the same whether your Delta table is partitioned or not. If you are working with a partitioned table, you have the additional option of outlining specific partitions that you wish to target with OPTIMIZE. The example below reflects this using the partition column “date” which is targeted using the WHERE clause.
%%sql --Compacting files only that have a partition year >= 2023 OPTIMIZE default.delta_table1 WHERE date >= '2023-01-01'
Note that running the OPTIMIZE command will not change the underlying data in the Delta table, meaning that running the same query both before and after the command is run will produce the same result set.
Data Skipping
Release: Delta Lake 1.2.0 | Minimum Synapse Runtime: Apache Spark 3.2
Data skipping is a feature that employs column statistics in order to provide more performant queries. This is accomplished by a process that automatically gathers and indexes column values for each column in a Delta table. The information is then referenced when querying the table.
If a column is being used to filter the Delta table during a read operation, the data skipping feature will avoid reading files that contain values outside of the filter criteria for that column. Be aware that collecting column statistics for data types such as string or binary is much more demanding than data types in numeric or date categories.
This feature does not require any initial configuration as it is enabled by default, though you can specify columns that you do not wish to collect statistics for. The following command will limit the number of columns for which statistics are collected.
%%sql --Set only the first two columns of delta_table1 for column statistics/data skipping ALTER TABLE default.delta_table1 SET TBLPROPERTIES ('delta.dataSkippingNumIndexedCols' = '2'); --Show table properties SHOW TBLPROPERTIES default.delta_table1
The SHOW TBLPROPERTIES output will reflect the value set by the ALTER TABLE command.
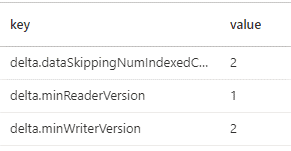
When setting this table property, the integer will represent the number of columns for which statistics are collected, starting on the leftmost side of the table. In this case, the first two columns will be able to take advantage of the data skipping feature. When setting the delta.dataSkippingNumIndexedCols property, consider keeping columns you wish to utilize for data skipping on the left-hand side of your Delta table.
Delta Table Restore
Release: Delta Lake 1.2.0 | Minimum Synapse Runtime: Apache Spark 3.2
Restoring in Delta Lake allows for reverting a Delta table to a previous table version. This feature can be useful in instances where a bad upsert has been made into a Delta table but should not be treated as a backup analytics solution. Restoring is made possible due to the Delta Log having the capability to reference files associated with previous table versions. Reading previous table versions is known as time travel.
The DESCRIBE HISTORY command will provide an output of a Delta table’s version history. The below screenshot provides the partial output for a table called “delta_employees”.
%%sql -- Retrieve the version/change history of the Delta table DESCRIBE HISTORY delta_employees

In this case, there are three versions available. After the table was initially created, two upserts were completed using MERGE operations. The current version (version 2) of the table can be seen below.

Before using the RESTORE command, previous versions can first be viewed using VERSION AS OF. Below, version 1 of delta_employees can be seen.
%%sql --View pervious table version. SELECT * FROM delta_employees VERSION AS OF 1

In order to restore to this version of delta_employees and make it the current version, the RESTORE command can be used with either the version number or the timestamp.
%%sql --Restore table to previous available version. RESTORE delta_employees TO VERSION AS OF 1 --Alternative method using timestamp. --RESTORE delta_employees TO TIMESTAMP AS OF <timestamp>
After running the restore, an output is returned providing a summary of the operation. While this metadata is also available in the version history of the table, it may also be a good idea to write this metadata to a log folder in the Azure Data Lake. The section on Operation Metrics will cover this in further detail.

The table history of delta_employees now reflects that a restore operation has been completed.

It is important to note that if the VACUUM command is used on the Delta table as part of routine maintenance, parquet files associated with table versions falling outside of the vacuum window will be truncated. The RESTORE command will only be able to revert to table versions where underlying parquet files are still available.
Z-Ordering
Release: Delta Lake 2.0.0 | Minimum Synapse Runtime: Apache Spark 3.3
Z-ordering builds on the optimize and data skipping features by providing the capability to collocate related records within the same grouping of files when using the OPTIMIZE command.
One or multiple columns can be specified for a z-order. Ideal column choices are those that are commonly used as filters when reading data. Z-ordering will allow for greater read performance as the engine will be able to take better advantage of data skipping to not scan files that fall outside a filter predicate during read operations.
Below is a small sample of records from a table called “delta_product”.
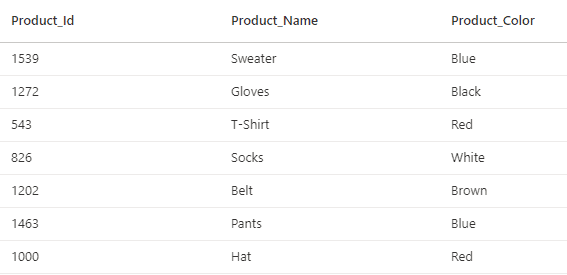
The table stores a Product_Id, Product_Name, and Product_Color. When reading data from this table, it is common to filter it by a single color. In order to make the read operations more efficient, the OPTIMIZE command will be run, including a z-order using the Color column.
%%sql OPTIMIZE delta_product ZORDER BY (Product_Color)
Running the command will compact the table into a smaller number of files. While this is being completed, Delta Lake will collocate records with the same Product_Color values into the same set of files. Next time the table is queried and filtered for a specific color, the query engine will utilize data skipping to avoid scanning the files that do not contain the color included in the filter.
Be aware that any columns that are not collecting column statistics should not be used for z-ordering as they will not be able to utilize data skipping.
Operation Metrics
Release: Delta Lake 2.1.0 | Minimum Synapse Runtime: Apache Spark 3.3
Newly added operation metrics for the existing SQL UPDATE, DELETE, and MERGE commands now return a dataframe with metadata related to the operation. Previously, these commands returned an empty dataframe after a completed execution. While these metrics can also be found within the output of the DESCRIBE HISTORY command, having them returned in a dataframe can make it much simpler for the developer to record the output in a log file or table.
To see this in action, the table below will be used as the target for a MERGE command.

Using the following code will allow for the metrics to be saved into a dataframe called “df_merge_metrics”. A detailed look at the MERGE statement used for this example can be found in this blog. The MERGE statement will insert a new employee and update the salary of Employee_2 into the table.
%%pyspark #Save MERGE statement dataframe output df_merge_metrics = spark.sql(""" Your SQL MERGE statement here """)
Reading the table reflects that the upsert has completed as expected.

Viewing the dataframe by using df_merge_metrics.show() will provide the operation metrics associated with the MERGE command that has successfully completed.

With the output saved to df_merge_metrics, the results can now be written to a file or inserted into a table in order to meet any logging requirements. Note that different operations will have their own set of columns available. The full list of definitions for each operation can be found in the documentation.
Conclusion
The open-source Delta Lake project continues to improve with new updates and features to each new release. As these make their way into Azure Synapse Analytics Spark Pools, it is important for teams using Delta Lake to stay on top of these changes as they often bring new analytic capabilities, additional resources, and performance improvements in analytical processing.
Exploring preview features in a sandbox environment is a great way to stay ahead of the curve in preparation for when updates become generally available. The Azure Synapse Analytics Blog is a great resource for keeping you up to date on what has been made generally available or released in preview.
Stay in the know – browse our blog posts for the latest news and best practices in Azure!
