
Data and analytics can help all businesses make better decisions, improve customer relationships, and enable strategic initiatives.
In the past, this required significant investments in hardware, software, and development to achieve. Today, even small businesses can gain these benefits with cloud-based analytics services like Azure Synapse.
Smaller businesses must be able to get the most value possible from their data. They do not have the deep pockets of large enterprises, so they need to choose the most cost-effective way to create improved outcomes from their analytics.
All the big players in the cloud-based analytics providers have a broad set of services on offer. They bill these services out based on the amount of the service you consume in terms of processing and storage costs.
The important thing for a small business to be aware of is that while some of these services have a high price for consumption, we can use others at a lower cost.
The cost of the services is not an uncommon issue for many companies. Over the last few years, people have come up with a similar approach to the choices available for a scalable analytics solution. This approach has become known as the data lakehouse architecture.
Sections:
Where to Start as a Small Business
A Small Business Data Lakehouse
What is a Data Lakehouse?
A data lakehouse is the combination of two existing analytical data architectures: the data warehouse, and the data lake.
Data warehouses have a 30-year history in business intelligence. They pull together data from multiple sources within a company for reporting and analysis.
Typically, the data is coming from databases that have a defined structure and processed into a new database structure optimized for complex queries used in business intelligence.
The processing approach emphasized the consistency, integrity, and quality of the provided data, but it can come at a high cost.
Data lakes arose about 10 years ago to handle data that came in a variety of less structured formats but also desired for analytical purposes. This is the data that comes from web APIs, web scraping, or other documents not formatted in terms of a relational database.
Data lakes are great at storing data at a very low cost; however, they lack the features available in a processed data warehouse solution. This often led to a lack of trust in the data and a loss of benefit to the company.
A data lakehouse is an architecture that brings together the best elements of data warehouses and data lakes. It uses the managed data processing and structures of a data warehouse on top of the low-cost storage used for data lakes.
For a small business with a limited budget, the cost of data storage is decoupled from the cost of data processing. By choosing data processing to compute services are based on the lowest cost processing required, they can build a solution that minimizes the ongoing operational costs to the company.
Where to Start as a Small Business
Data architectures can be very complex. Cloud-based analytics platforms like Azure provide services for companies of every size and potential use case.
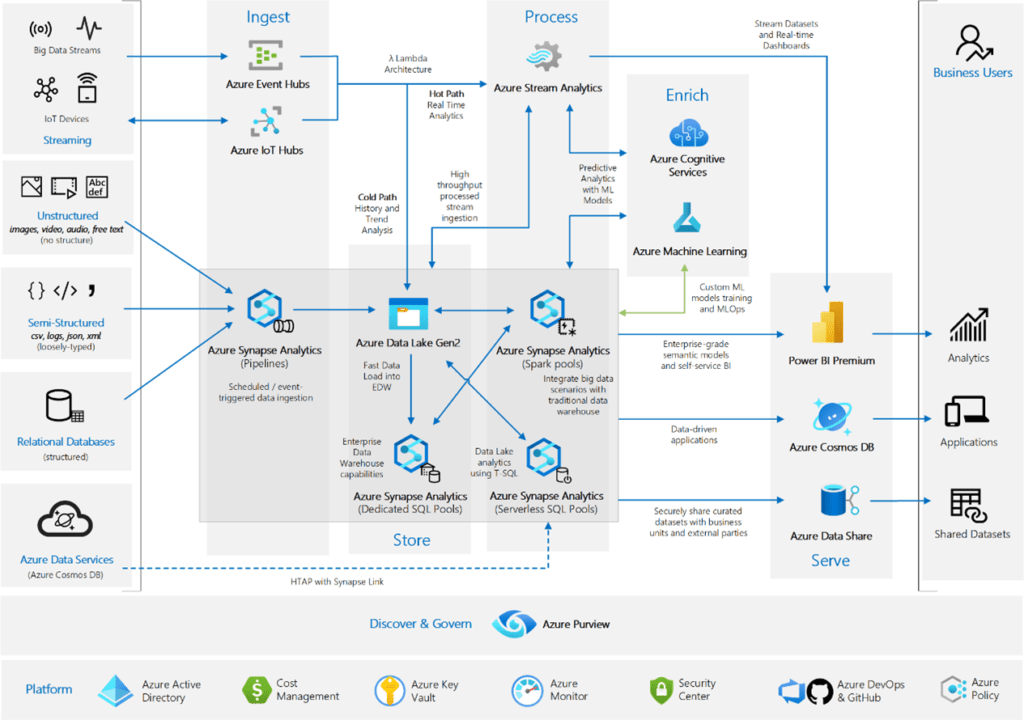
Microsoft Enterprise Analytics
A small or mid-sized company does not need all this complexity. The best approach is to build out an analytics program by taking small incremental steps and grow into more complex data architectures.
Much of what they offer and what is possible to use will never be used by smaller companies.
For example, real-time analytics are not needed unless you have dedicated people making minute-by-minute decisions throughout the day. A smaller firm should avoid that complexity and cost and build to a slower standard.
In most cases, daily data updates are more than adequate. If you need more frequent updates to your analytics, then consider near-real time with hourly or 15-minute updates. Which can be provided using the simpler low-cost services available.
Small and mid-sized companies rarely have the volume of data necessary to justify the use of something like a Dedicated SQL Pool with its enterprise-level capabilities. They build it to operate on a scale that most companies simply do not need. And while it is immensely powerful, this power comes at a steep cost.
It is best to not use this service until your companies’ data volume has grown to a scale – where processing it in a timely manner has become a problem.
So, let’s simplify this down to something more reasonable for a smaller company. We still want the platform management and security features built into Azure.
Most smaller companies are going to start with data from relational databases and third-party web APIs.
Then we need to pull this data into our data lake as a way to process it at the lowest cost possible. And once we have our analytics data ready, we want to make it available to our users. This leaves us with a basic data lakehouse architecture like this:
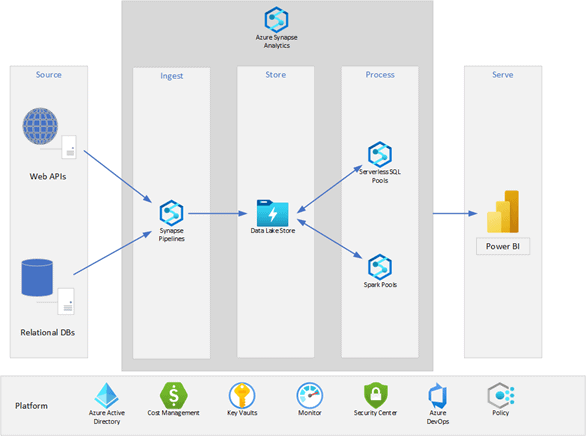
A Small Business Data Lakehouse
Most small or mid-sized businesses are looking to make use of their existing data in the systems they operate their business with. Only rarely will they be looking to do analytics on unstructured data like text, video, or audio.
While a data lake can handle this data, it is a use case beyond almost all small businesses.
This means that almost all source data will come from either a relational database or a web API. Data that comes from a relational database is structured data, as it has a known structure based on tables and fixed relationships.
Data that comes from a web API is semi-structured, this means that the underlying structure of the data is not known but the data as provided has some sort of loosely typed structuring like a JSON or XML format.
To get this data into the data lake, we use a data orchestration tool like Azure Synapse Pipelines. This provides a cost-effective way to access, pull, land, schedule, and manage the processing of data within the lakehouse.
If the data is well structured and relatively simple, then you can use serverless SQL to process the data into an analytic data model ready for consumption. Serverless SQL can also process non-complex semi-structured data like most JSON files from a web API.
Only move to the toolset offered with Spark Notebooks when your source data or the processing required becomes more complex. An example of a complex source is an API that provides a JSON file with a ragged hierarchical structure.
A more complex processing requirement is the use of delta lake structures within your data lakehouse. Spark notebooks running on a Spark pool are cost-effective, but it is a step up in complexity from serverless SQL.
As a small business, you want to use the simplest and most cost-effective services for as much of your needs as possible.
You should also use a defined file structure with your data lake. Separate your data into folders based on readiness for analytical use. Typical structures used are the raw/staged/curated seen in data lakes or the bronze/silver/gold seen in delta lakes.
The difference being that in a data lake you are dealing with flat files and in the delta lake you are dealing with Spark DataFrames.
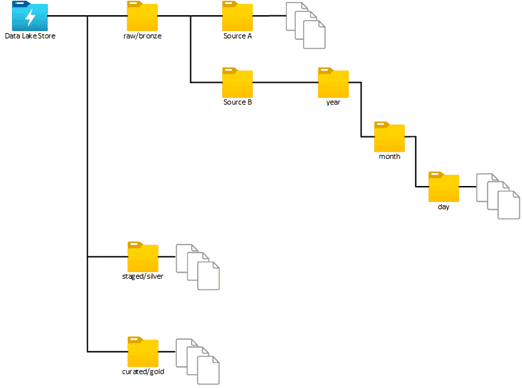
Raw/Bronze: files/tables containing raw unprocessed data from the source system fully representing the source data as given (CSV, JSON, XML, etc.). If the data is pulled incrementally, then a date-based partitioning scheme should be used.
Staged/Silver: files/tables containing a refined semi-processed view of the data. Fields from various raw/bronze sources can be joined to enrich the data.
Curated/Gold: files/tables that provide fully processed analytical data. Business level aggregate data ready for consumption.
Conclusion
Data warehousing has come a long way over the years. Now we have a modern data architecture known as the data lakehouse that can bring analytics to businesses of all sizes. As with all cloud-based data platforms, there is a lot of choice in the services you can use. The data lakehouse paradigm is constantly developing and a company adopting it must use a disciplined approach. By focusing on a limited selection of these services, a small or mid-size company can build out an analytic solution at a very reasonable cost.
