
When hearing the term “Delta Lake”, most will think of the Databricks platform. While there is no doubt that Databricks is the industry leader when it comes to Spark, did you know that you can also develop Delta Lake solutions within Azure Synapse Analytics?
Apache Spark 3.1 has become generally available in Synapse this past September and with it has come an upgrade to Delta Lake 1.0.
In this blog, we will review the capabilities that a Spark and Delta Lake combination brings to the table, as well as a demo to help get you started.
Throughout the blog, we will reference the Delta.io documentation page as it is a great resource for getting started with Delta Lake.
Sections
- Introduction
- What is Delta Lake?
- Synapse Environment Setup
- Creating Sample Data
- Creating a Delta Table
- The Delta Log
- Upsert with Merge: Initial Table Load
- Upsert with Merge: New Records
- Delta Table History
- Looking Back with Time Travel
- Delta Table Maintenance: Compact
- Delta Table Maintenance: Vacuum
- Combine Delta Lake with Serverless SQL Pools
- Conclusion
What is Delta Lake?
Delta Lake acts as an additional layer over the data lake, from which a Lakehouse architecture can be developed. This enables the ability for Spark to perform ACID transactions on top of data lake storage solutions. Below are some key features of Delta Lake that caught my interest and led me to test it out in Synapse.
- Delta Lake is an open-source project, meaning that it is available without licensing costs and the project is available to view on GitHub.
- Provides the ability to easily upsert (insert/update) and delete data using familiar syntax in Spark SQL (MERGE).
- Builds on top of the Lakehouse Architecture allowing for the separation of storage and compute resources.
- The option to view table change history and read previous table versions.
For more on the Data Lakehouse architecture, check out Steve Richardson’s blog.
Synapse Environment Setup
To follow along with this demo you will need the following Azure resources.
- Azure Synapse Workspace
- Azure Data Lake Storage Gen 2 Storage Account
- Apache Spark 3.1 Pool
If you are creating a new Synapse Workspace, then you will create a data lake storage account during the setup process. Spark pools can be created from the “Manage” blade of a Synapse Workspace.
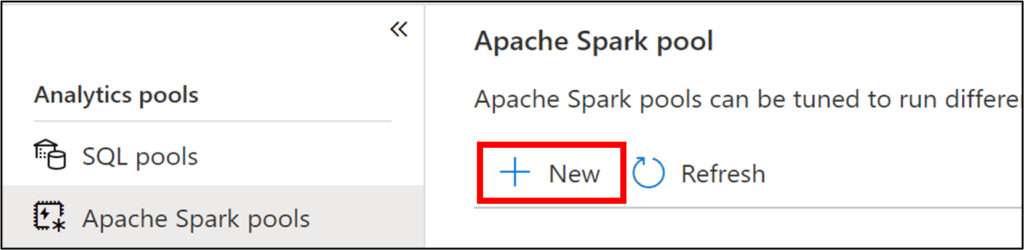
Keep in mind that spark pools are a compute resource that will incur costs by the minute for nodes that are in use. For this demo a small node size and a node range of 3-3 will be sufficient.

Creating Sample Data
We will start by creating a new notebook under the “Develop” blade of the Synapse Workspace and assign a Spark pool to the notebook, we can leave the notebook language set to PySpark. In the example screenshot below, “aspdev01” is the name of the Spark pool in my Synapse Workspace.

We will populate the first code cell of the notebook with the below code. This code will create two dataframes named dfOriginal and dfUpdates. We will use these dataframes as sample datasets for inserting into a Delta table later.
When running the code cell, we will see the output of both dataframes. Note that the first dataset (dfOriginal) contains two employee salary records while the second dataset (dfUpdates) changes the salary for Employee_2 and adds a new record for Employee_3.

In order to easily query these dataframes as tables using Spark SQL in later steps, we will create temporary views by running the code block below.
Creating a Delta Table
Let’s now create a Delta table to support our sample data that we created in the previous section. This will be a table that supports a type 2 slowly changing dimension, which will allow for keeping track of current employee salaries, as well as historical salary information.
We will use the below code in a new code cell. The top line of “%%sql” will change the context of the code cell from PySpark to Spark SQL.
%%sql -- Create Delta Lake table, define schema and location CREATE TABLE DELTA_Employees ( Employee STRING NOT NULL, Salary INT NOT NULL, BeginDate DATE NOT NULL, EndDate DATE NOT NULL, CurrentRecord INT NOT NULL ) USING DELTA -- specify data lake folder location LOCATION '/Delta_Demo/Employees/'
Notice that the syntax for creating a Delta table in Spark SQL is very similar to that of T-SQL. This CREATE TABLE statement will create a table called “DELTA_Employees” in the default Spark database (also called a “Lake Database” in Synapse) associated with my Spark pool. The last two lines of the statement will specify that the table will be in Delta format and the data lake folder to store any files for the table.
Note that the column datatypes use Spark datatypes and not SQL datatypes, for example, we have STRING instead of VARCHAR. When creating a Delta table also be aware of table partitioning as it can help with performance when querying tables with many records.
We will run the code cell to create the Delta table.
The table is now present in the default Spark database. When browsing the data lake path specified in the last line of code, we can also see that a “_delta_log” folder has been created.

The Delta Log
All folders that support Delta table files will have a “_delta_log” folder present within them. Within this folder, you will find log entries in the form of JSON files that keep track of transactions, as well as table metadata changes. When first creating a table, we can see the first log file has been generated.
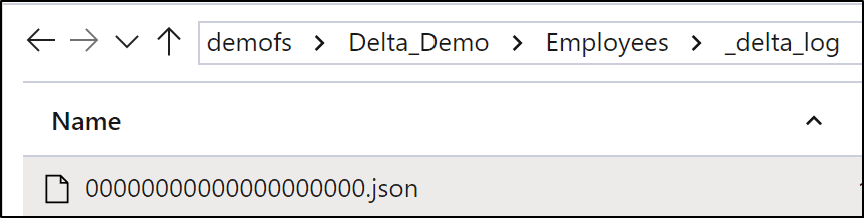
Every time a change action is performed against the table, a new log file will be created. Log files do not contain a full history of table changes but rather any changes that have occurred since the last log file. Together all Delta log files contain the full table history.
Log filenames increment by the next available integer value, we will be able to see this shortly in the later sections of this blog. By default, logs are retained for a period of 30 days and cleaned up automatically during checkpoints.
Upsert with Merge: Initial Table Load
One of the big draws of Delta Lake is the ability to insert and update records into your data lake.
Next, we will populate the new Delta table with an initial dataset and then see how we can both insert and update (upsert) the table with new records. To accomplish this, we will be using the Spark SQL MERGE statement. We won’t get into the weeds on the specifics of merge statement syntax as both Delta Lake and Databricks have some good documentation to reference.
We will place the below code into a new code cell. This merge statement will insert records from the Employee_Orginal dataset view into the DELTA_Employees table while also populating metadata values for each row such as BeginDate, EndDate, and CurrentRecord.
This statement will also check the table to see if an employee already has a record present in the table. If a match is found and there is no change to the employee’s salary, no action will be taken. If a match is found and the employee’s salary has changed, the EndDate and CurrentRecord columns of the matched record will be updated to reflect them as no longer being the current record for that employee.
The new record with the updated salary value will then be inserted into the table and flagged as the current record for the employee. When running this code cell all records will be inserted as the DELTA_Employees table is currently empty.
%%sql -- Merge statement to handle upsert of dfOrginal dataset into DELTA_Employees table MERGE INTO delta_employees t USING ( SELECT emp.Employee AS MergeKey, emp.* FROM Employee_Original AS emp UNION ALL SELECT NULL AS MergeKey, emp.* FROM Employee_Original AS emp JOIN delta_employees AS de ON emp.Employee = de.Employee WHERE de.CurrentRecord = 1 AND emp.Salary <> de.Salary ) s ON t.Employee = s.MergeKey WHEN MATCHED AND t.CurrentRecord = 1 AND t.Salary <> s.Salary THEN UPDATE SET t.CurrentRecord = 0, t.EndDate = (CURRENT_DATE) WHEN NOT MATCHED THEN INSERT (Employee, Salary, BeginDate, EndDate, CurrentRecord) VALUES (s.Employee, s.Salary, CURRENT_DATE, '2999-12-31',1)
Once the statement completes, we can run a select statement to validate that the records have been inserted.
The contents of the Employee_Original dataset are now present in the Delta table.

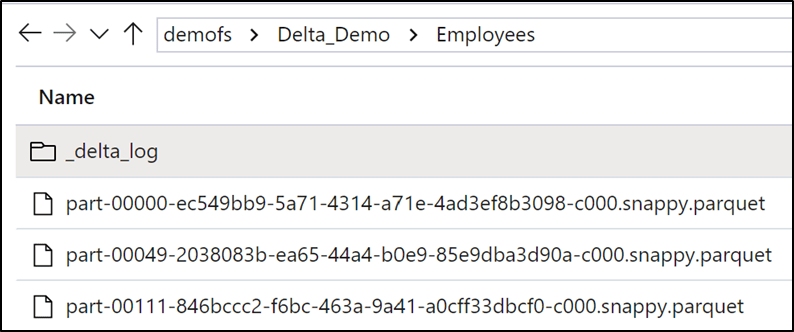
Let’s take a look and see what this looks like in our data lake. You will notice that we now have parquet files present in the Delta table folder, these are the files that the Delta table is currently referencing. The delta log folder now also contains a new JSON file as we have performed a change action against the table in the form of a merge statement.
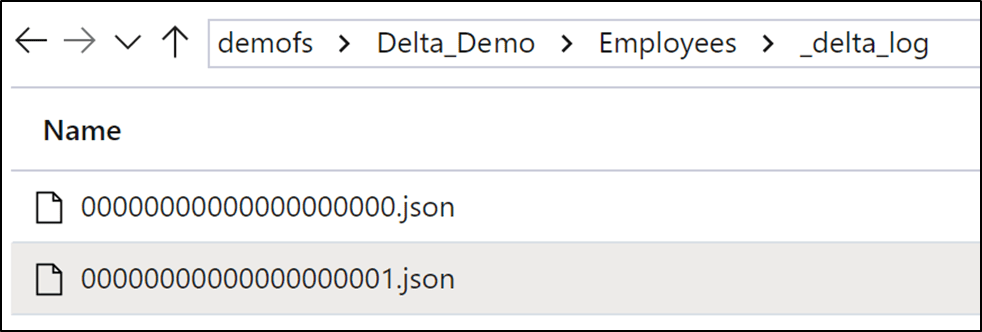
Upsert with Merge: New Records
We will now utilize the same merge statement from the last step to insert new records from the Employees_Updates dataset view into the Delta table. The only change will be updating the source dataset to use the Employee_Updates dataset instead of Employee_Original.
As the Employees_Updates dataset has a new salary value for Employee_2 and a new record for Employee_3, we should see a change to rows for Employee_2 and a new row for Employee_3. We will paste the below code into a new code cell and run it to complete a second merge statement.
%%sql -- Merge statement to handle upsert of dfUpdates into DELTA_Employees table MERGE INTO delta_employees t USING ( SELECT emp.Employee AS MergeKey, emp.* FROM Employee_Updates AS emp UNION ALL SELECT NULL AS MergeKey, emp.* FROM Employee_Updates AS emp JOIN delta_employees AS de ON emp.Employee = de.Employee WHERE de.CurrentRecord = 1 AND emp.Salary <> de.Salary ) s ON t.Employee = s.MergeKey WHEN MATCHED AND t.CurrentRecord = 1 AND t.Salary <> s.Salary THEN UPDATE SET t.CurrentRecord = 0, t.EndDate = (CURRENT_DATE) WHEN NOT MATCHED THEN INSERT (Employee, Salary, BeginDate, EndDate, CurrentRecord) VALUES (s.Employee, s.Salary, CURRENT_DATE, '2999-12-31',1)
Once the statement finishes, we will run the same select statement on our Delta table to view the updated table state.
%%sql SELECT * FROM DELTA_Employees ORDER BY Employee
Employee_2 has now had their previous record updated to no longer be listed as current, and their new salary has been inserted as the current row. Employee_3 has also had a row inserted. There are no changes to Employee_1 as their salary did not change.

As expected, we can now see additional parquet files in the Delta table folder, as well as an additional JSON log file in the delta log folder.
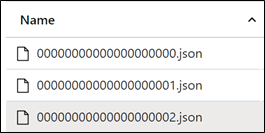
Delta Table History
Another useful feature of Delta Lake is the ability to retrieve a history of table operations performed on Delta tables. The DESCRIBE command returns a table which allows the audit of what action was performed, when it occurred, and who performed the action. In the command below we will specify the DELTA_Employees table to retrieve the history using Spark SQL.
%%sql -- Retrieve the version/change history of the Delta table DESCRIBE HISTORY default.DELTA_Employees
Below is a subset of some of the table columns. The table version will increment whenever a table operation is performed. We can also see the timestamp of the operation as well as what operation occurred. The “operationParameters” column will provide some detail on the operation. In this case we can see the merge predicate, as well as the match/no match predicates. In the “operationMetrics” column we can view information about rows affected in the table. Delta Lake will keep 30 days of history by default.

Note that these are only a few of the available columns that the table returns, the documentation page provides a full listing of all available columns and descriptions.
Looking Back with Time Travel
Time travel provides the capability to read previous versions of a Delta table. This feature is very handy if you want to view the state of your table before and after an operation has occurred. Delta Lake can accomplish this by reading parquet files associated with older versions of the table. The Delta transaction log files that we looked at in previous steps are still referencing the old parquet files as they are still present in the Data Lake, this allows us to read these table versions.
Here we will load version 0 of the DELTA_Employees table.
# Load a previous version of the DELTA_Employees table into a dataframe df = spark.read.format("delta").option("versionAsOf", 0).load("/Delta_Demo/Employees/") df.show()
As expected, an empty table is returned as version 0 is the creation of the table.

When looking at version 1 of the table, we can see the state of the table after the first merge statement that was run.
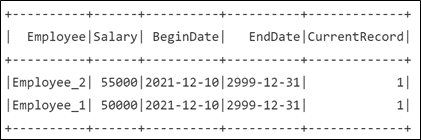
While you shouldn’t treat the time travel feature as a mechanism for backing up your data, it can be a good option for cases where a bad upsert has been made into a table. Time travel could be used to load a last known good table state into a dataframe and overwrite the existing table. A Delta table will only have 30 days of previous versions available by default as it relies on the Delta log files for referencing older data.
Delta Table Maintenance: Compact
If table operations occur on a frequent basis, a Delta table can have an accumulation of many files stored in the underlying data lake. When querying the Delta table read times can be affected as many files will need to be scanned and read whenever a query is preformed. The compact of a table can help by reading all current Delta table files into a dataframe and then writing the dataframe to a specified number of files.
The compact statement below will read the current version of the Delta table and write out to a single file.
# A compact will let us write out the contents of our Delta table into a specified number of files. (spark.read .format("delta") .load("/Delta_Demo/Employees/") #delta table folder to read from .repartition(1) #number of files to write .write .option("dataChange", "false") #do not change the data .format("delta") .mode("overwrite") .save("/Delta_Demo/Employees/")) #location to write new file(s)
After running the compact statement, one new file is created in the data lake location of the Delta table. Also note that all previous files still exist in the folder as they are still referenced by older table versions in the delta logs.
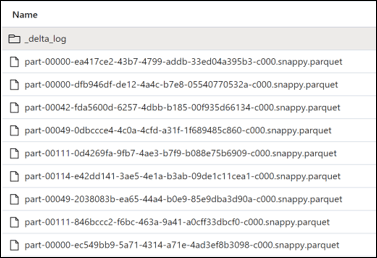
A compact statement will show as a write operation in the Delta table history.

Delta Table Maintenance: Vacuum
As we have seen in previous sections, Delta Lake does not delete old parquet files when change operations occur as these older files are still referenced by previous table versions for a default period of 30 days. After the default retention period has passed, the parquet data files are not deleted even if they are no longer referenced by log files. In order to efficiently manage data lake storage costs, the VACUUM command can be used to remove old data files.
Vacuum has a default retention setting of 7 days. This means that when running the command, it will delete any data files associated with table versions that are more than 7 days old, unless otherwise specified.
It is also possible to override the default 7-day retention by specifying a number of hours in the vacuum statement.
Vacuum also provides the ability to do a “dry run” where you can list which files would be deleted.
%%sql --Vacuum files where table version is older than 10 days VACUUM default.DELTA_Employees RETAIN 240 HOURS
Be aware that if you attempt to run a vacuum command with a timeframe lower than the default, Spark will return a warning advising the command cannot be run. This is a safety mechanism that can be turned off, but it is advised to not change this as it increases the risk for corrupted data.
Combine Delta Lake with Serverless SQL Pools
Throughout this blog we have used a Spark pool to query the DELTA_Employees table. While Spark provides top notch performance when querying files in Delta Lake, another available option for querying Delta Lake is to utilize the Serverless SQL Pool in a Synapse Workspace. Serverless SQL has a couple of advantages such as no wait time for Spark nodes to spin up, as well as incurring costs by amount of data processed vs Spark’s per minute of compute model.
Serverless SQL pricing typically floats around $7 CAD per TB of data processed.
Querying Delta tables with Serverless SQL Pools is very similar to that of a folder containing regular parquet files. Below is an example of a query that will select records from the DELTA_Employees table. Specifying delta format in the select statement lets Serverless SQL know that it needs to look for a Delta log in the destination folder. Note that Serverless SQL uses T-SQL syntax.
SELECT * FROM OPENROWSET( BULK 'https://storageaccount.blob.core.windows.net/demofs/Delta_Demo/Employees/', --Specify Delta Lake folder FORMAT = 'delta') as rows --Specify delta format ORDER BY Employee
As expected, records from the current Delta table version are retrieved.

I am looking forward to testing out how Serverless SQL query performance compares to Spark using larger datasets in the future.
Conclusion
Delta Lake enables Spark’s ability to perform insert, update, and delete operations into data lake storage which allows for simple development of Lakehouse architectures. Additional features such as version history and time travel further add to Delta Lake’s ability to provide audit history and data resiliency. In this blog we have covered some essentials of Delta Lake such as how to create a Delta table, populate a table using the merge statement, and the basics of table maintenance. With the integration of Delta Lake and Serverless SQL in Synapse Analytics, the Lakehouse becomes an efficient contender to consider for analytics solutions.
